Hidden Markov Models
Gesture sequences often have a complex underlying structure, and models that can incorporate hidden structure have proven in the past to be advantageous. Most existing approaches to gesture recognition with hidden state employ a Hidden Markov Model or suitable variant (e.g., a factored or coupled state model) to model gesture sequence.
Hence, one of the methods applied to our dataset and to the extracted features was a Hidden Markov Model.
The Goal
We have trained a Hidden Markov Model and applied with the following goals:
- Discriminate gestures made by the same subject (Rita)
- Determine how the previous classifier behaved when applied to another subject (Manu)
- Determine how soon can a gesture be predict, i.e. how many frames of a gesture does one need to determine it.
The Features
We have chosen to features that are related to the sum of distances (sum of all distances, sum of distances from centroid to the fingers and sum of distances between the three fingers). The reason for not using Dx, Dy, Dz, is that by themselves these features are not very good to discriminate the different gestures. One could think that sum of Dy (vertical axes) to be good feature to choose but this is not true since the hand does not stay perfectly parallel to ground while the gesture is being made.
The figures below show sum of all distances and sum of distances between fingers for both datasets (Rita and Manu).
For the sum of all distances (first two figures) it is possible to see that the grasp is the gesture that has the largest variation in values. On the push gesture the distances remain almost constant throughout the gesture for the Rita Dataset but they vary in a constant manner for Dataset Manu. The reason for this is that the subject Manu started the gesture with fingers apart and would closed them throughout the gesture. This detail will be proven important when trying to generalize the gesture classifier to different datasets. The point gesture is in between the other two types of gestures regarding variation of sum of distances.
The last two figures show the same graphs for the sum of all distances between fingers. It is possible to observe that once we extracted the centroid from the data, and only considered distances between fingers, the gestures become more separable.
The sum of distances from the centroid to the fingers, not presented here, did not show much more improvements, in terms of discriminating the gestures than the sum of all distances.
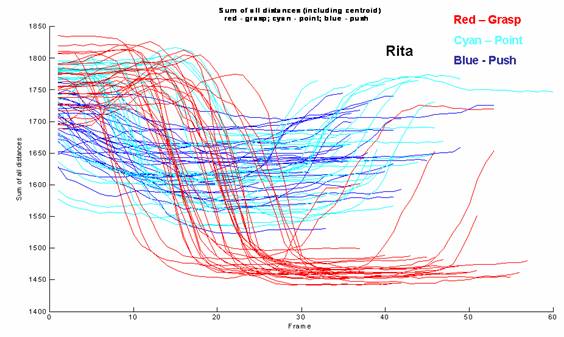
Sum
of all distances for dataset Rita
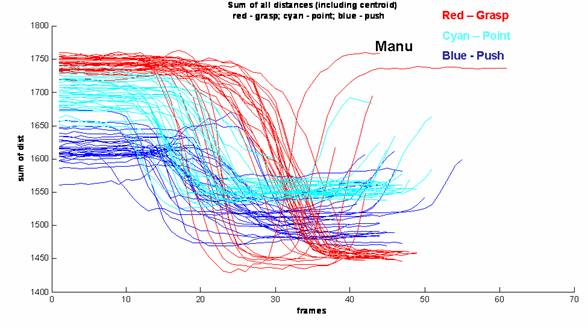
Sum
of all distances for dataset Manu
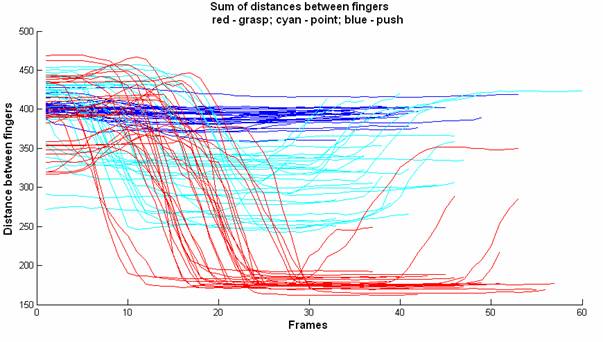
Sum
of distances between fingers for data set Rita
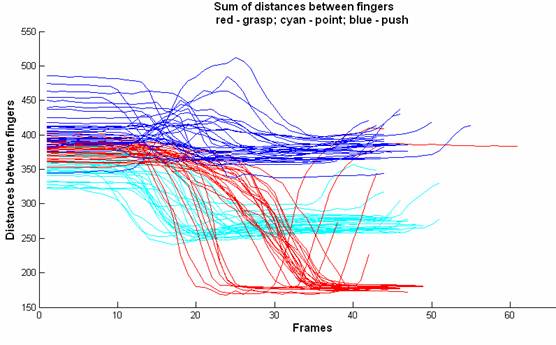
Sum
of distances between fingers for data set Manu
The Results
We have trained a hidden Markov Model from 1 to 4 states for each class (gesture). The best results obtained are presented in the next section.
A) Train and test on same subject (Rita)
This was made by 10 fold cross validation. Train on 20 examples and tested on 10. The best results obtained are presented in the figure below. These are results for the sum of all distances.
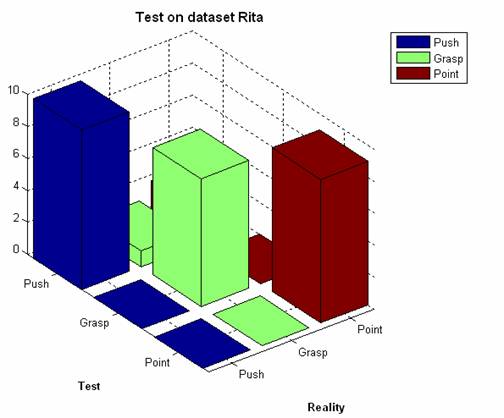
The correspondent confusion matrix is the following:
|
|
|
Reality |
||
|
|
|
Push |
Grasp |
Point |
|
Test |
Push |
10 |
1 |
2 |
|
Grasp |
0 |
9 |
0 |
|
|
Point |
0 |
0 |
8 |
|
The best resulting HMM had 1 State for the push and 2 states for Grasp and Point.
B) Train on Rita and test on Manu
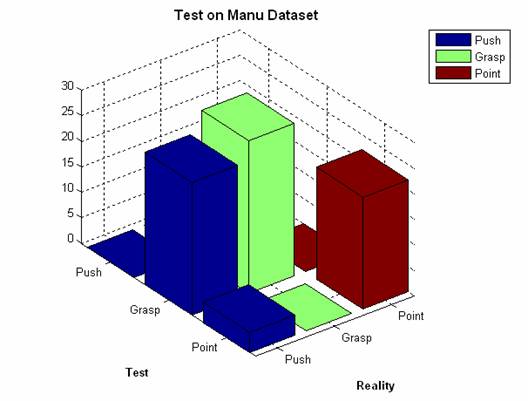
The correspondent confusion matrix is the following:
|
|
|
Reality |
||
|
|
|
Push |
Grasp |
Point |
|
Test |
Push |
0 |
0 |
8 |
|
Grasp |
26 |
30 |
0 |
|
|
Point |
4 |
0 |
22 |
|
The HMM work well on identified Grasp and Point but totally failed when trying to identify The Push. We believe the reason for that is that Manu was opening and closing is fingers while pushing and the chosen feature is not able to “capture” very well the relative movement of fingers on all directions.
However we though that if one used feature 3, i.e the sum of distances between fingers the problem would at least alleviate. The next figure show the results using the feature sum of distance between fingers.
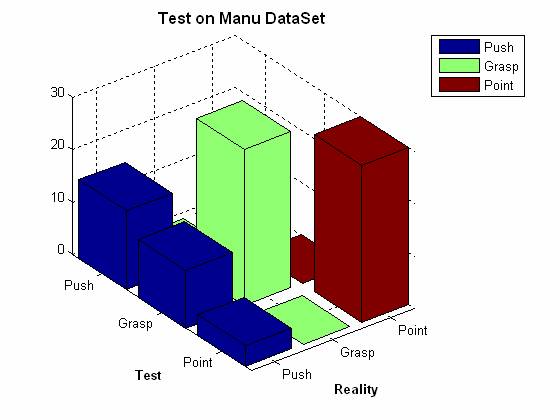
The correspondent confusion matrix is the following:
|
|
|
Reality |
||
|
|
|
Push |
Grasp |
Point |
|
Test |
Push |
15 |
0 |
0 |
|
Grasp |
11 |
30 |
0 |
|
|
Point |
4 |
0 |
30 |
|
By using only the sum of distances between fingers we were able to considerably improve the results. However we are only still able to identify 50% of Manu push. A solution for this problem could be for example to use a combination of features (for example sum of distances between fingers and Dy) in order to better “capture” the relative movement of the fingers.
C) Prediction of movement
We have cut the sequences on several different lengths in order to study how the accuracy of the classifiers changes. The results are presented below.
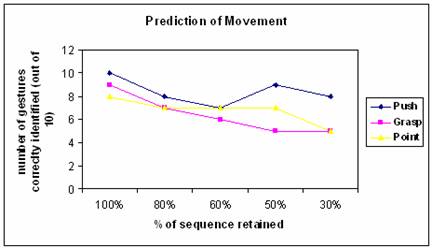
One can observe that when less than 50% of the sequence is retained the accuracy to identify Point and Grasp is almost around 50%.In fact these two gestures start being confused and you are better off guessing between the two.
The next figures show the confusion matrix at chosen points.
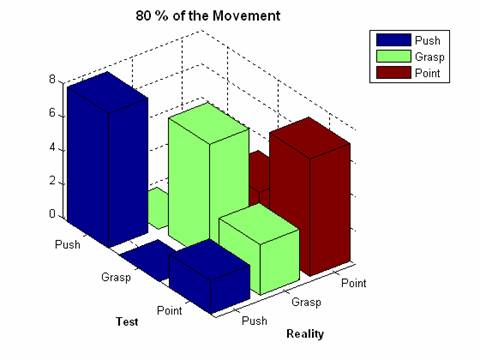
The correspondent confusion matrix is the following:
|
|
|
Reality |
||
|
|
|
Push |
Grasp |
Point |
|
Test |
Push |
8 |
0 |
0 |
|
Grasp |
0 |
7 |
3 |
|
|
Point |
2 |
3 |
7 |
|
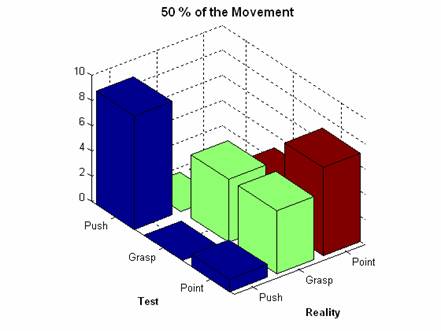
The correspondent confusion matrix is the following:
|
|
|
Reality |
||
|
|
|
Push |
Grasp |
Point |
|
Test |
Push |
9 |
0 |
0 |
|
Grasp |
0 |
5 |
3 |
|
|
Point |
1 |
5 |
7 |
|
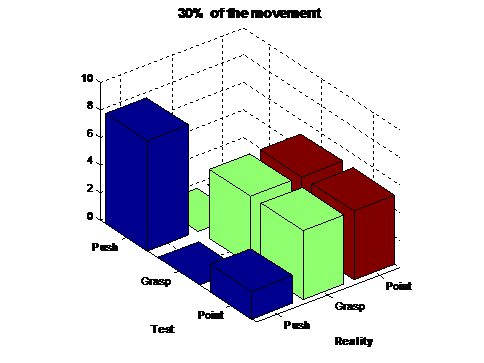
The correspondent confusion matrix is the following:
|
|
|
Reality |
||
|
|
|
Push |
Grasp |
Point |
|
Test |
Push |
8 |
0 |
0 |
|
Grasp |
0 |
5 |
5 |
|
|
Point |
2 |
5 |
5 |
|
Summary and Comments
The HMM technique performed well on one person
data, just by looking at the sum of all distances. It also performed well when
tested on another person doing the same gestures on two of these gestures. It
failed on the push! By getting ride of
the markers on the back of the hand we were able to boost the performance of
the HMM and able to correctly identify all Grasp and Points on Manu dataset.
One was also able to identify 50% of the Push.
As future work we suggest, in order to further boost performance is to use a Dynamic Bayesian Network and include a second feature – Dy – to better take into account relative movement of fingers
Also, another limitation of HMM is the requirement of conditional independence of observations. In addition, the hidden states are selected to maximize the likelihood of generating all examples of a given gesture class, which may not necessarily be the best to discriminate between gestures. To address this problem other techniques, like Conditional Random Fields, have being used, with success to identify Hand and Arm gestures.