Feature selection
The "Original 11"
After determining the character of the data using the descriptive statistics above, we used a greedy forwards feature search to arrive at 11 features which seemed to best discriminate those listings which were fully funded from those which closed unfunded. These included:
- Credit Grade
- Amount Requested
- Borrower Rate
- Debt to Income Ratio
- Group membership (true/false)
- Has an image (true/false)
- Current delinquencies
- Delinquencies last 7 years
- Open credit lines
- Income
- Bid count*
While "bid count" proved to be a very useful feature in distinguishing unfunded listings from funded loans, we ultimately removed it, since it is an artifact of the bidding process rather than a characteristic of the loan application.
We performed a principle component analysis of these features to project the data down to 2 and 3 dimensions to gauge the separability of the data.
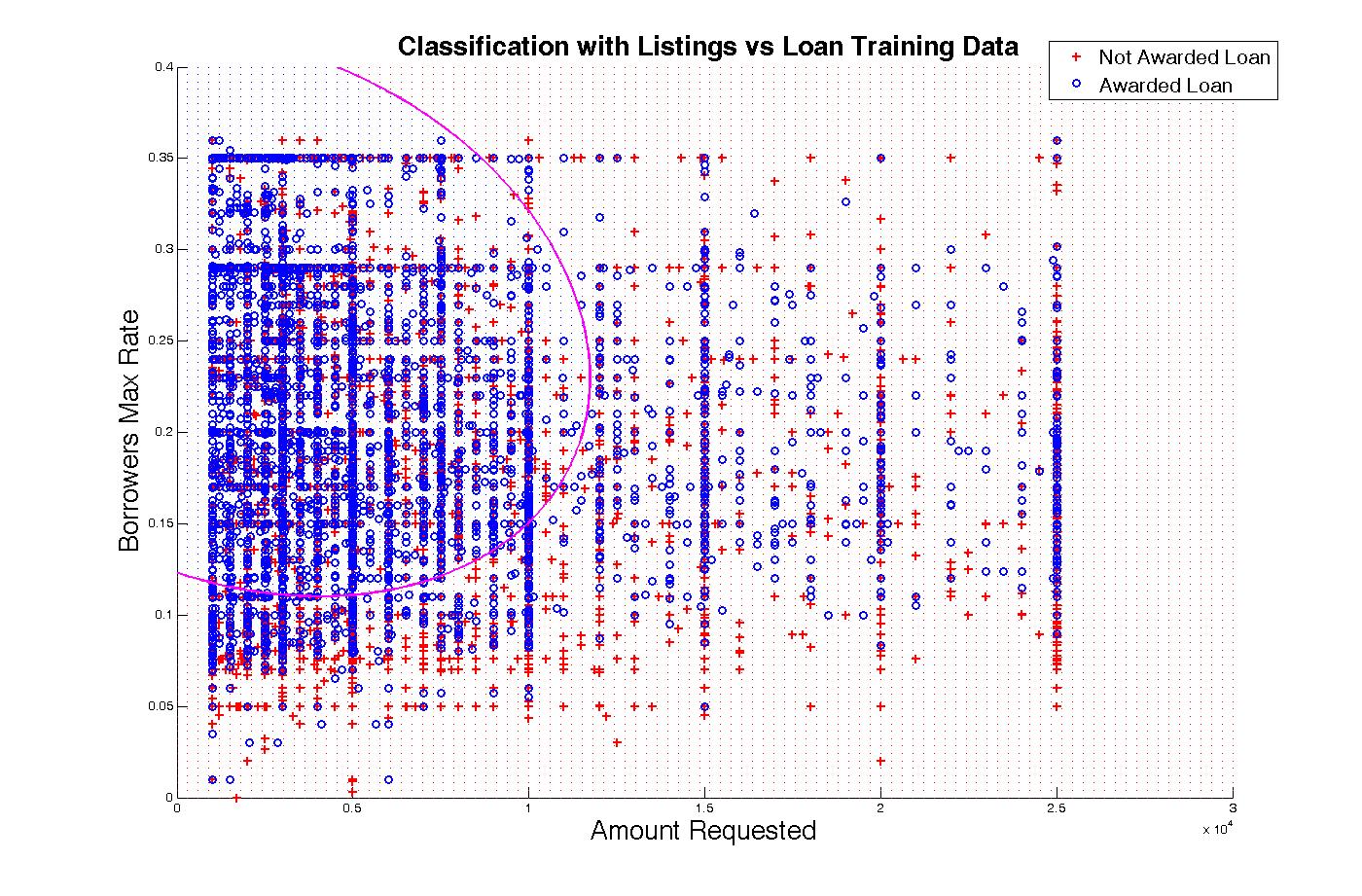
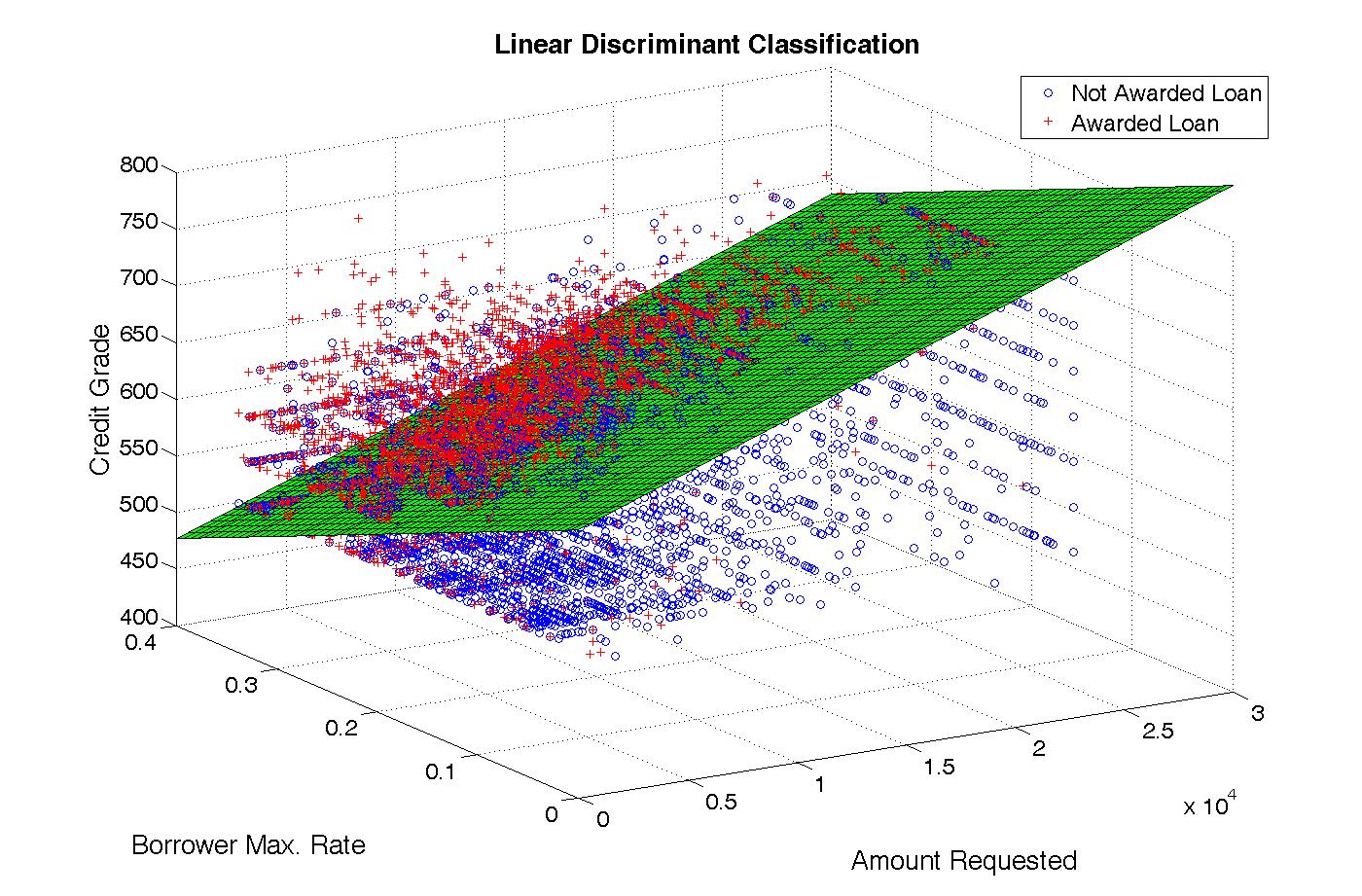
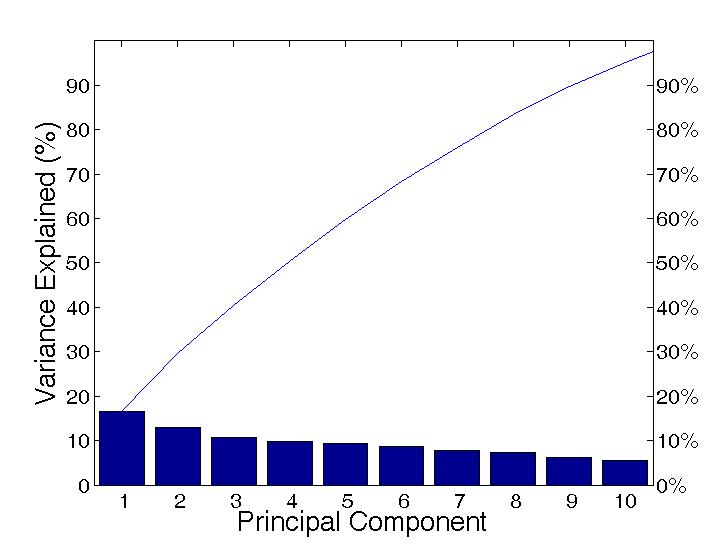
The following shows the portion of the variance present in the 10-feature population which was contributed to by each of the top 10 principle components:
The "96"
Unlike traditional bank loans, in which applicants are scrutinized based largely on their financial profile, peer to peer lending involves much more direct human communication, including pictures and descriptions. Thus, we were interested in seeing if we could take advantage of the descriptive textual features available in the data set.
To do this, we calculated the frequency of every word, pair of words, and set of three words in the listing descriptions, titles, and member endorsements. We used these features to construct tables of those words which most discriminate the data set (full description results, full title results).
Description words
| Loans | Listings | Difference | Words |
|---|---|---|---|
| 0.44 | 0.58 | 0.14 | cards and other |
| 0.29 | 0.42 | 0.14 | monthly expenses housing |
| 0.44 | 0.58 | 0.14 | clothing household expenses |
| 0.41 | 0.54 | 0.13 | and other loans |
| 0.42 | 0.56 | 0.14 | other expenses |
| 0.29 | 0.43 | 0.14 | expenses housing |
| 0.44 | 0.57 | 0.13 | clothing household |
| 0.45 | 0.58 | 0.13 | car expenses |
Title words
| Loans | Listings | Difference | Words |
|---|---|---|---|
| 0.024 | 0.058 | 0.010 | cards and other |
| 0.022 | 0.042 | 0.007 | monthly expenses housing |
| 0.021 | 0.058 | 0.005 | clothing household expenses |
| 0.009 | 0.054 | 0.005 | and other loans |
| 0.062 | 0.056 | 0.022 | other expenses |
| 0.049 | 0.043 | 0.017 | expenses housing |
| 0.015 | 0.057 | 0.012 | clothing household |
| 0.026 | 0.058 | 0.011 | car expenses |
An additional problem we encountered was dealing with the presence of null values in the database. Many of the features, including numeric ones, have null values &emdash; often with high priors. To preserve the information carried by the null value, we split these features into two columns: one which contains a binary value indicating whether the field was null or not, and the second field representing the value of the feature (or zero if it was null). Based on these parameters, we arrived at a list of 96 features.
We then implemented a sequential forwards floating search with which to choose a subset of those 96 features which best describes the data. (forwards floating search code) The forwards floating search algorithm turned out to be very slow, despite using a simple linear discriminant as an evaluation function. To speed the calculation, it proved necessary to either further subsample the feature set (and thus increase the bias of the feature selection) or to set a cap on the number of features considered (thus decreasing the optimality).
This graph shows a tiny subset of the forward floating
search algorithm's progress. The backtracking mechanism is
what allows this algorithm to escape some local minima.
However, better clusters of features are often not found
until more features have been chosen, which might then
propagate all the way back to smaller numbers of features.
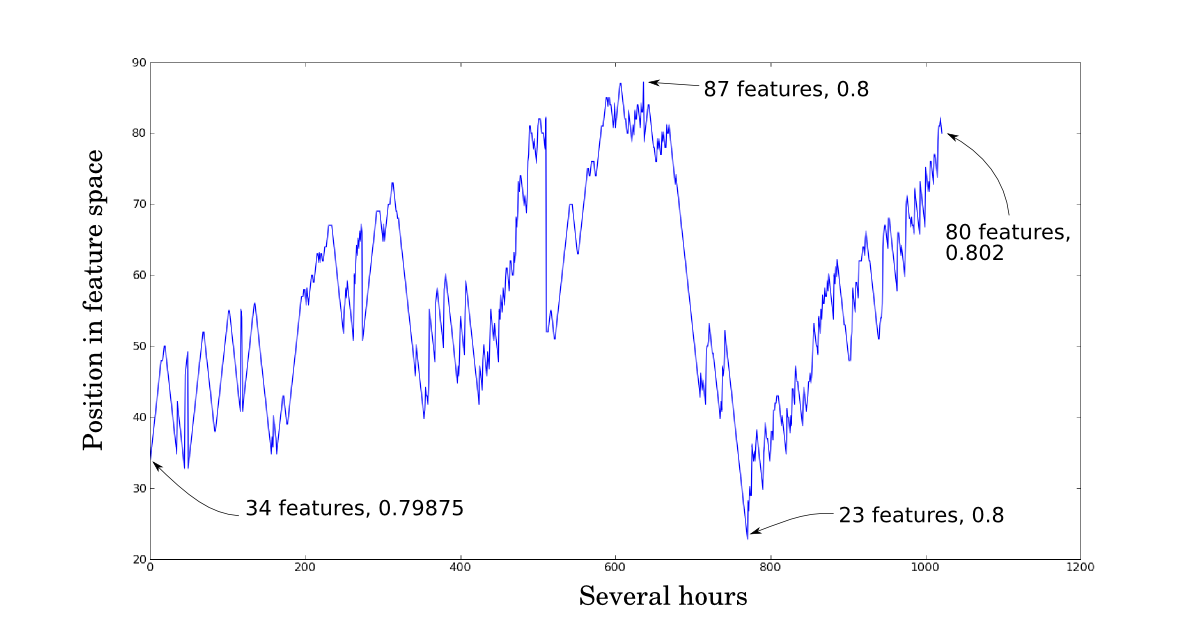
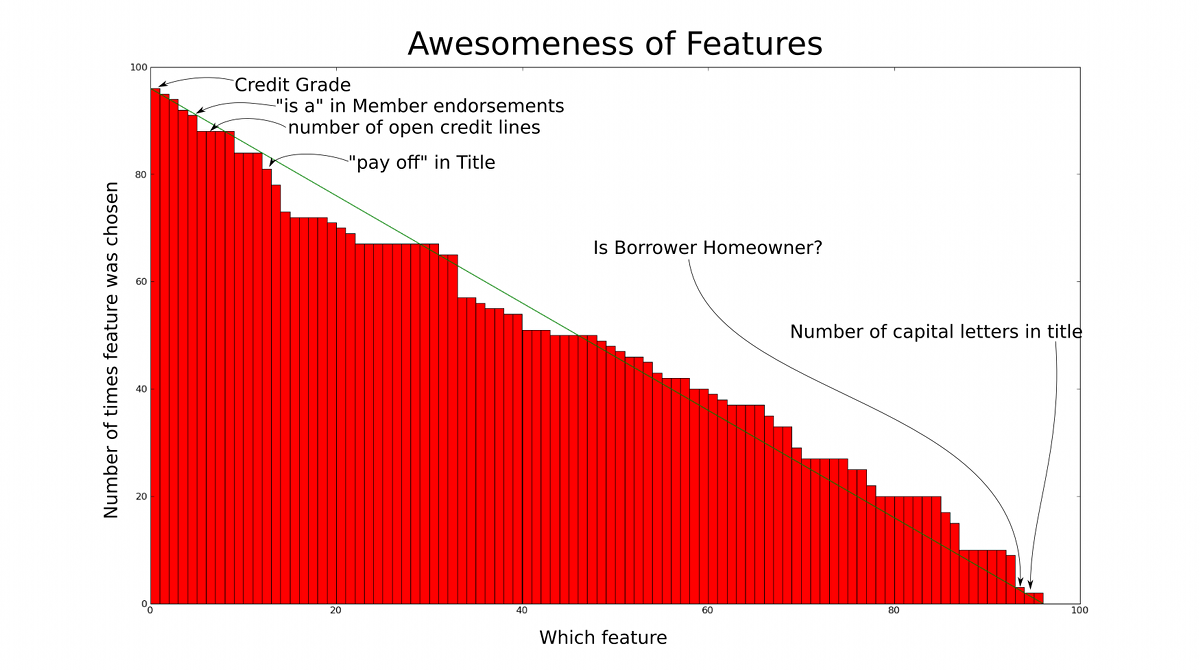
This graph shows the number of times each particular
feature was chosen, giving an indication of how good the
feature is at discriminating the data. If the features had
each been statistically independent, one would expect that
the graph would show a straight decreasing line. The
extent to which the graph exhibits a stepping pattern
indicates the dependence of some features.
Results: the best feature sets found for each feature size from 1 to 96 features for:
- loans vs. unfunded listings, 10000 samples from each class
- paid vs. defaulted loans, 1000 samples from each class
- Translation of feature number to field
- Source code: Forwards floating search python code