Human Classification with Amazon Mechanical Turk
Lending at Prosper.com differs from lending at traditional institutions in several important ways. Unlike banks, prosper lenders can weigh more than “just the numbers.” In addition, peer to peer lenders may have motivations beyond a return on investment, for example doing social good or helping a friend. Finally, individual lenders lack the complex risk assessment models that banks utilize everyday.
Using Amazon.com’s Mechanical Turk platform for distributed micro-tasks, we conducted two experiments to see if we might bolster machine learning processes with human-aided classification.
We used the Turk for two tasks: image classification and assessment of “trustworthiness.” Both experiments were conducted with three individual judgments per image. We create a template for judgments, represented below, and randomly selected 200 images drawn from the Prosper database. Fifty percent of images corresponded to listings that converted to loans and been paid in full; the other fifty percent were listings that had never converted to loans. Each image was identified by a number; we also recorded whether the listing had been a. fulfilled and paid or b. never filled.
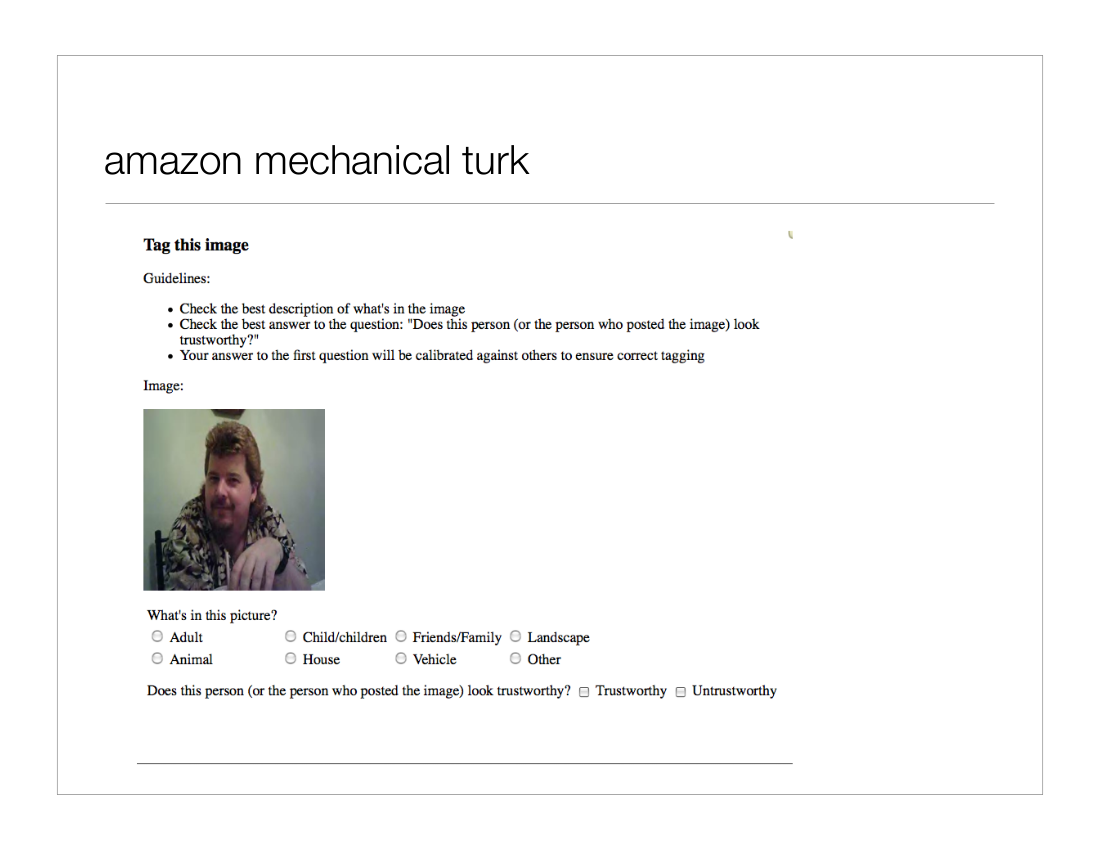
After data collection we analyzed results to check for internal consistency, as well as to identify confusion in classification. We also tested to see if the human judgment of trustworthiness was correlated with whether or not the loan was filled and paid.
Results
Image classification
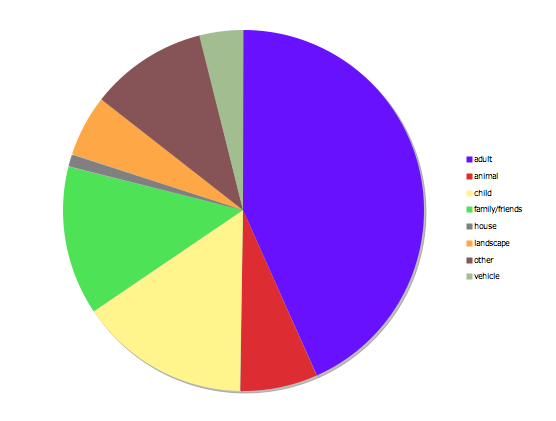
There was a high level (89.5%) of perfect consensus in image classification. Of the 10.5% of images that did not elicit a unanimous categorization, two root causes were identified. 9.5% of all images lacked consensus but were tagged with two of the following labels: Adult, Child/children, and Friends/Family. This indicates some confusion about the labels themselves; indeed, spot checks of these images showed groups of young friends of or mixed-age individuals.
The remaining 1% consisted of two or more tags across non-human and human categories. Examining images so-tagged revealed that they contained vehicles as well as people. In addition, AMT logs showed longer judgment time (and thus likely, decision-making time) for these photos, relative to the judging turker’s average time. This indicates that the classification task was likely non-trivial compared to the others performed by the same turker.
Trustworthiness rating
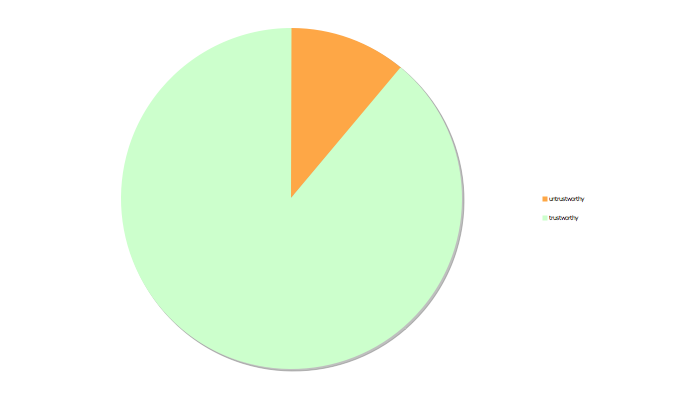
There was 11% disagreement for the trust rating. In addition, no statistically significant correlation was found between trust rating and whether or not the associated listing was funded and paid off.
Future work might consider a different experimental design. For example, two photos could be should side by side and judges could be asked to assess which is “more” trustworthy. Or, the photos could be put in context using descriptions from the prosper loans themselves.
Discussion
Overall, image classification with the mechanical turk is a promising option. With consensus checks for consistency, a high accuracy rate can be attained. The use of AMT for image tagging has been borne out by other studies. The use of the turk platform as a tool for subjective judgment, however, requires further refinement.