Email Optimization
Generally we receive between 50 to 200 emails per day, which need to be sorted attended to and acted upon. Once processed, they are rarely seen again. The messages are stored but their data and our interaction with that data is not used in any meaningful way, except for the occasional retrieval via search. There is no history, no wear, for something that gets so many hours of our life and careful interaction; why is the program the same each time we come back to it? Goals: streamline and automate the processing of email reading and replying; use methods (namely visualization of behavior) to provide reflective feedback on our use, so as to inform our behavior; make evident our wear and patterns of interaction, that they inform the representation of the data. How do electronic interfaces become worn or worked in, how do they display their use, and how do they behave differently as a result.
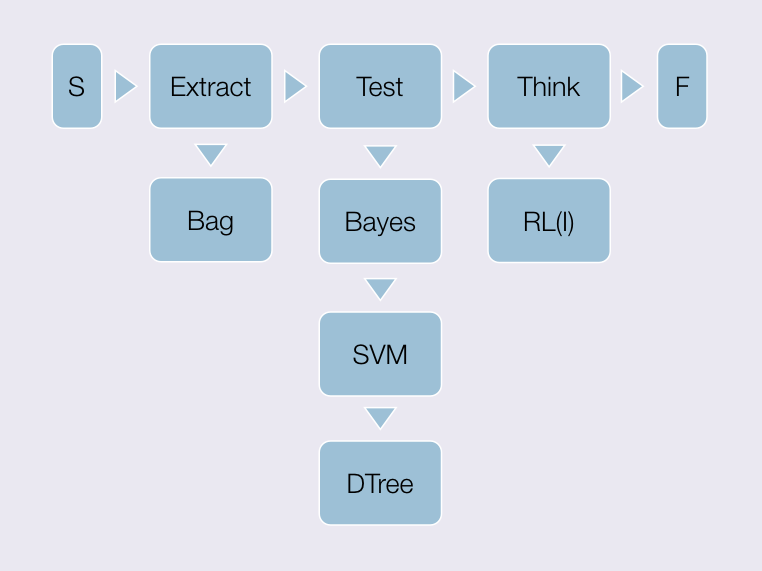
Method
The methodological approach follows the general procedure of organizing the data. extracting, then applying a series of machine learning techniques to better understand, both the structure of the data and the likelihood of different approaches to perform, automated classification of the information.
Data
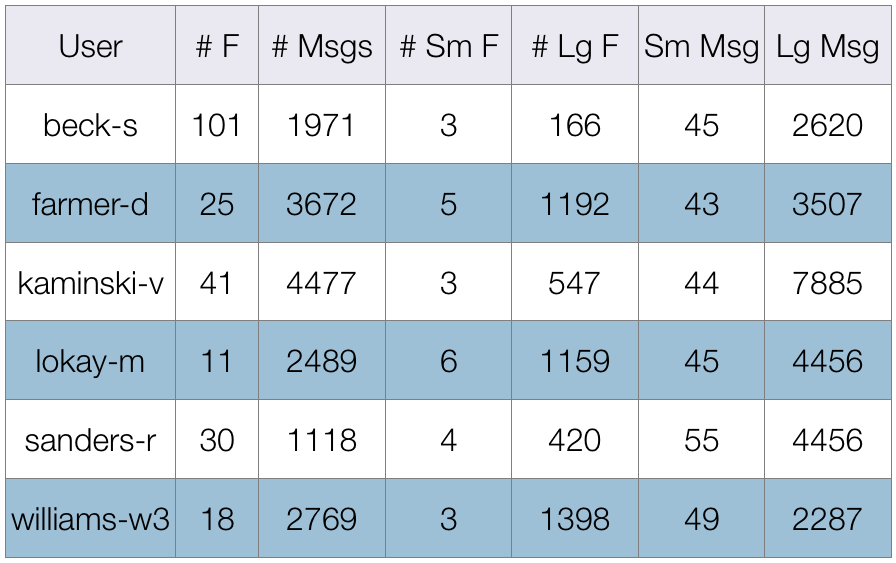
The project began with using live data from users via a web interface, but it became apparent that the development of algorithms while simultaneously having to support and debug an end user interface to use, was a poorly constructed setup. Subsequently I chose to make use of the enron data set specifically the 6 users listed to the right. This was chosen due to the large number of folders maintained by these users.
As far as data extraction was concerned, the meta data, as well as a tokenized, word frequency count from the body and subject was constructed (ignoring html tags). These cleaned data sets can be downloaded as SQLite3 databases for further study. The tables include:
create table msgs (
id INTEGER primary key AUTOINCREMENT,
messageid INTEGER,
internaldate DATETIME,
unixtime INTEGER,
efrom TEXT,
eto TEXT,
ecc TEXT,
ebcc TEXT,
flags TEXT,
subject TEXT,
body TEXT,
RFC822 TEXT,
words TEXT,
wordcounts TEXT
);
create table folders (
messageid INTEGER,
name TEXT
);
create table wordcount (
word TEXT UNIQUE,
count INTEGER DEFAULT 0,
foldername TEXT
);
“ An email system is a dynamic environment. In an email system, folders and messages are constantly being created destroyed, and reorganized. For text classification, this has two ramifications. First, the number of classes may change over time. Second, the content associated with class labels may change over time. ”
Reasoning
Begin by conceptually trying to understand the relationship to how we process an incoming mail item, and what features become of value to the end user. Most naively, on the decision of which box to put a new mail item into... Is it from someone who I always put in this box? What is the temporal periodicity of arrivals to this category? Is the content similar? (the old term frequency similarity).
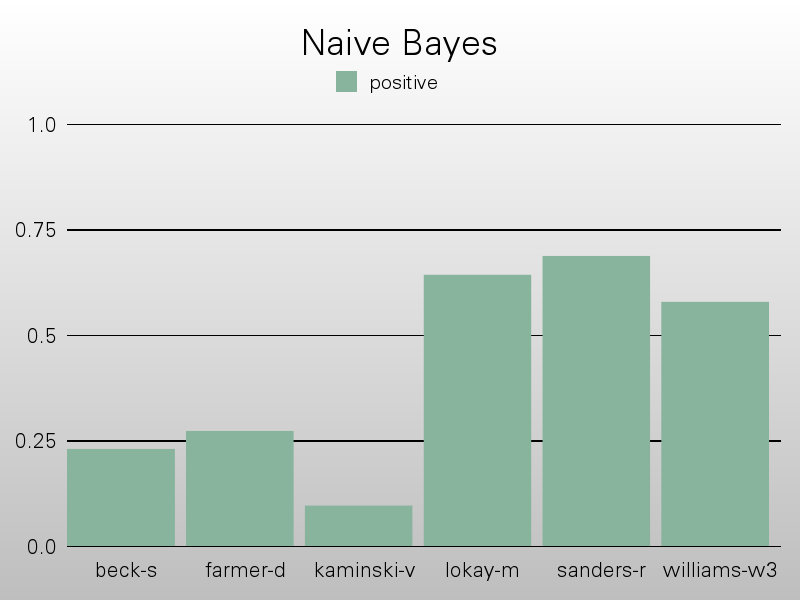
Naive Bayesian Approach
The naive bayesian approach is the most widely used approach, for spam classification, but has many short comings when re-applied as a general classifier. The algorithm works on the "naive" assumption of independent attributes. Here each attribute is the tokenization of the email message. In following with a separate training and testing set, there was a 90/10 split respectively.
The results were low, but expectedly so in some ways, since they were trying to classify at times across almost 100 categories (though generally closer to 25). And using a vector space of hundreds of words.
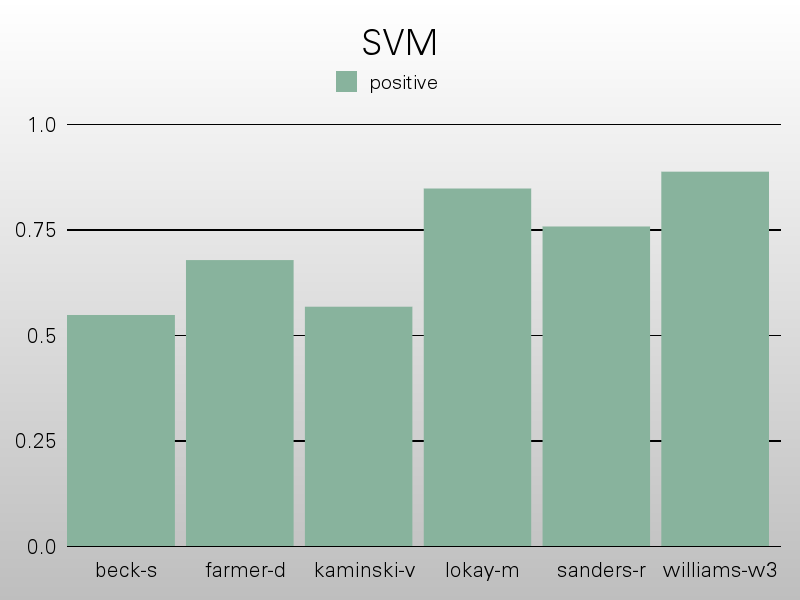
Support Vector Machines
The support vector machine process, using the Polynomial kernel function, though producing a marked improved on the performance of classification, was marred by its immense time complexity. Rendering it theoretically highly functional but practically unusable for this process. Especially since something such as email classification, which is a dynamic process would need constant retraining of the data. The data input followed the same source as used in the Naive Bayesian approach. Again following a 90/10 split of training and testing.
Continuous and Discrete Decision Trees
The decision tree process is mainly one of iteratively determining, the attribute of carrying the most information, and thus the most useful in determining classification in the system. This comes mainly from Shannon and Weaver's formula for the number of bits used to encode a stream of data. We thus measure the amount of information in each attribute, and choose that for the subsequent node in the tree.
As far as this specific data source is concerned, there is the important process of attribute selection. This needed to be done both with a discretion of the data source as well as for the construction of the continuous random variables. The discretization process involved; binning the time into slices of month, day, and year; binning the from space into each user; binning the to space into each user; and finally binning the 1st word, 2nd word and 3rd word of the subject, and the body.
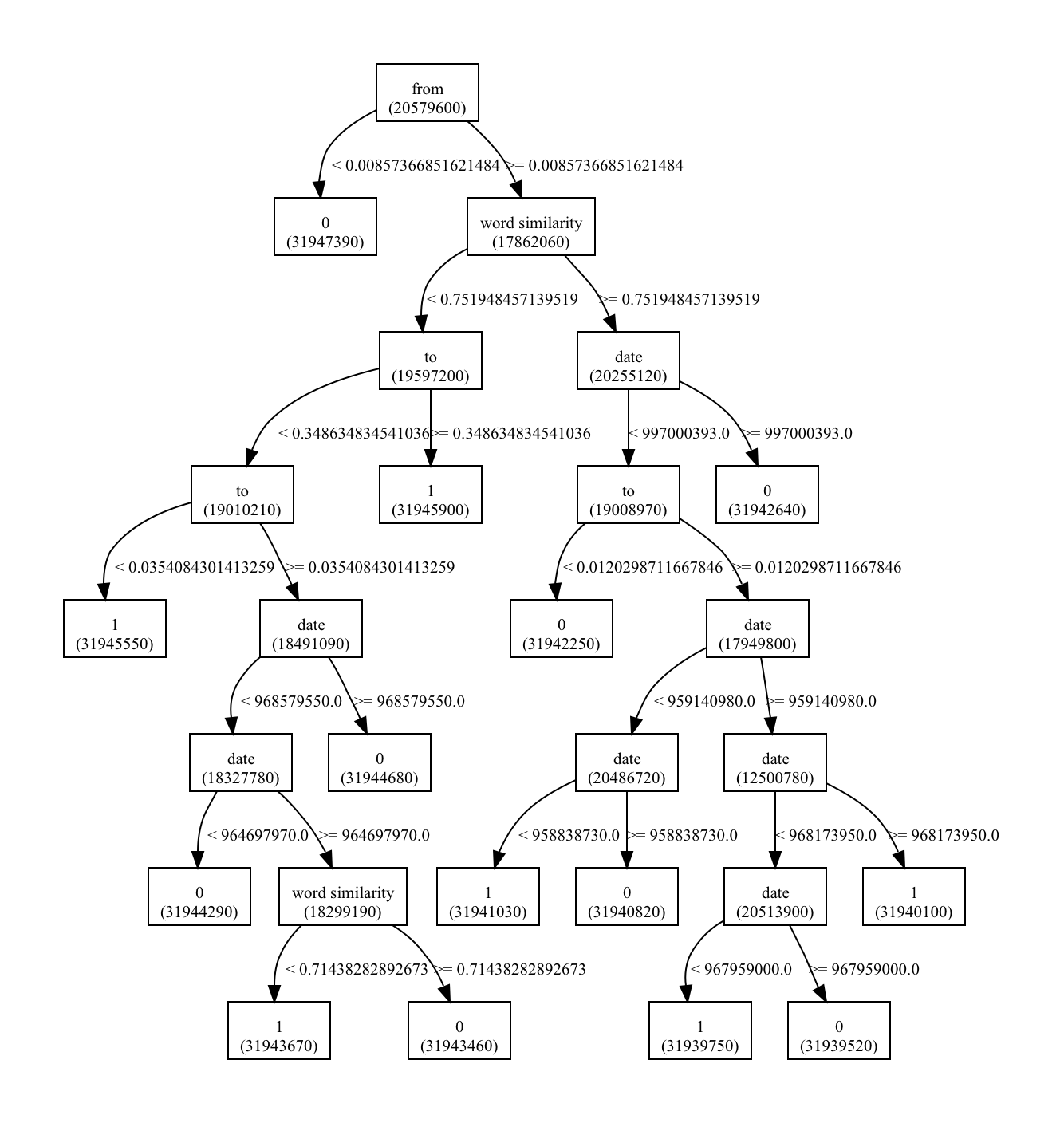
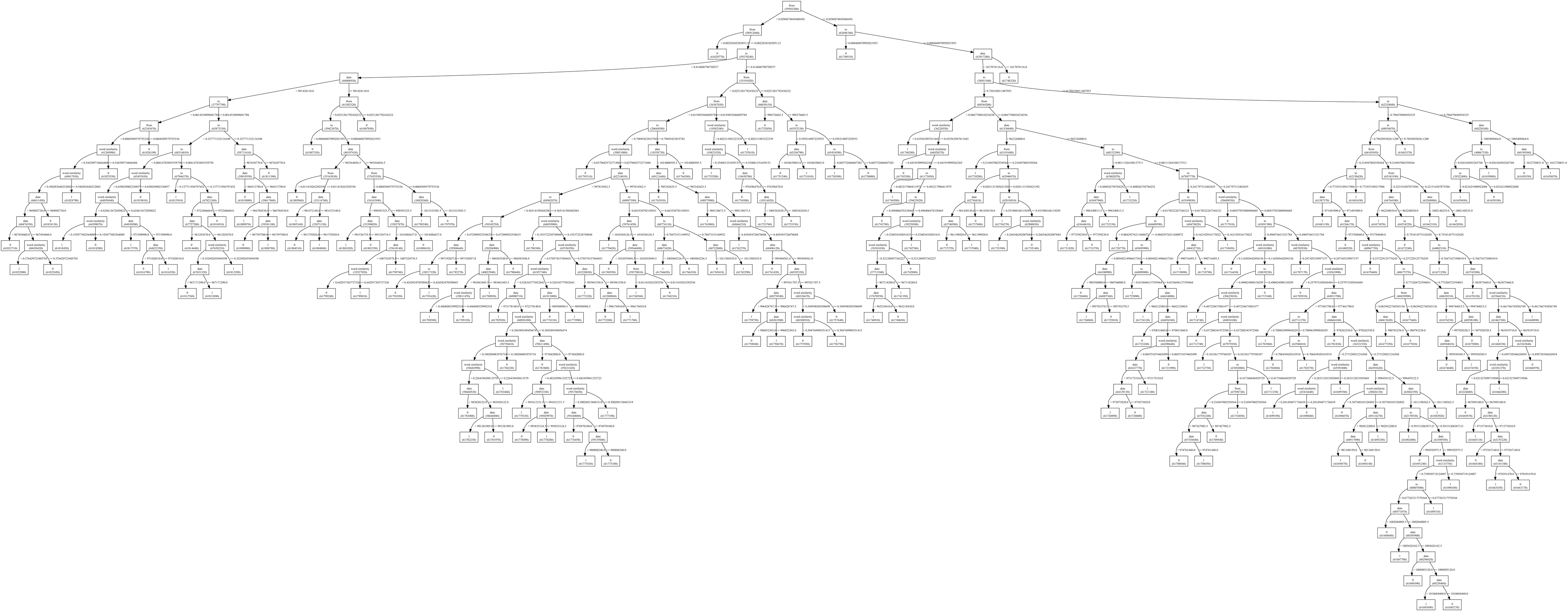
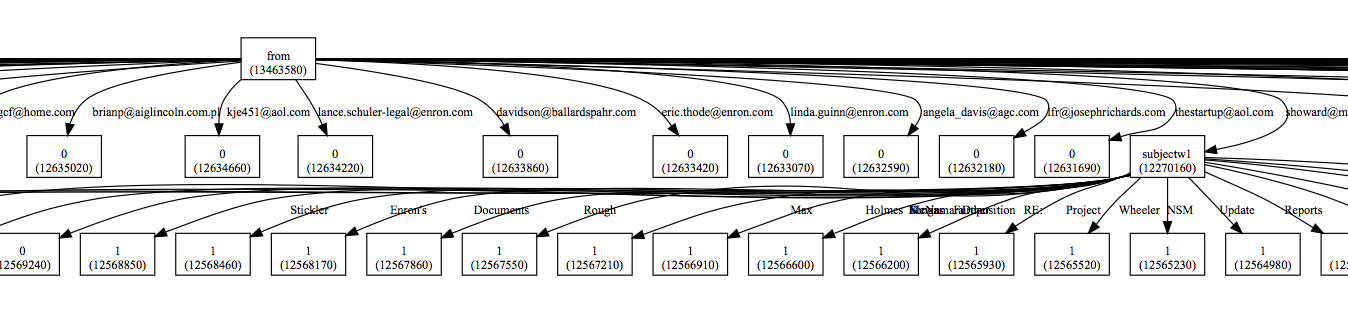
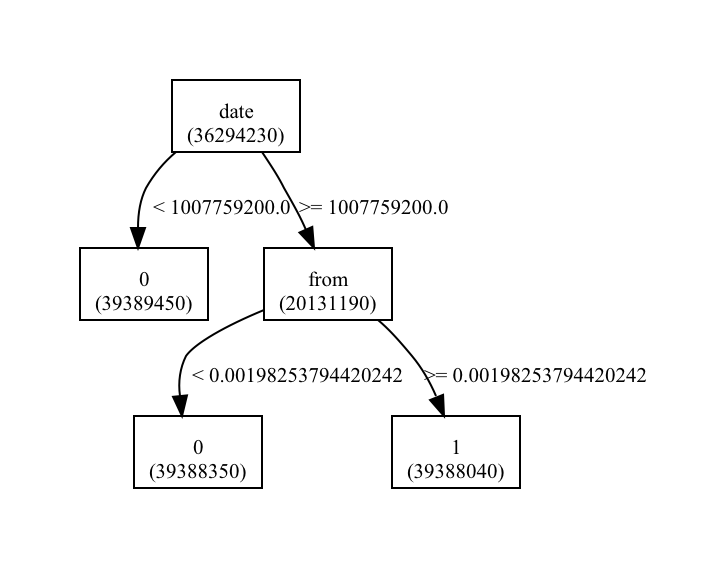
While the decision tree approach functioned extremely well in helping to understand the structure of the relationships between mail features, its actual classification performance was extremely low. I feel it would strongly benefit from a less binary ordering, where you maintain the distribution for a longer time in the tree.
Live Site
Functioning implementation for use with live data. Link below (will update to final hosting site when Necsys gives me the hostname). For now you can access it here. Let me know if there is a problem as for the moment it is hosted on my local machine.
Actor Critic Reinforcement Learning
Additional approach of an actor critic method for interpreting mail structure I believe could be extremely powerful. Like in the quote above email is a dynamic structure, and the constantly shifting goal is difficult for traditional machine learning approaches to approximate. I am currently in the process of implementing my own version of reinforcement learning. Specifically the Actor-Critic Method. In contrast with the Q-learning (more popular), but requires a finite state horizon, which email does not have.
Next Steps
I believe that exploring the social weighting will prove more useful. Similar to del.icio.us but for mail, where starring a message causes its interest value to increase for the global list. Implemented with a web server storing large hash table of message_id’s with star frequencies. Give the poor performance of classification techniques, focus should I think be placed on a more secondary stream of interest from known low importance input streams. The high amount of volume on a mailing list to the list, provides a better opportunity for the practical use of these techniques, because failure to classify correctly means only that one would read an extra message they may have wanted, or miss a message from mailing-list they deemed relatively unimportant to begin with. If it could learn for a specific mailing list why I stay subscribed to it and what else is of value, that could be useful. And since each mail on the list shares the same global message_id, that data could be attached to a socially relevant global score to further importance value on a message thread via a collective intelligence weighting model, which has not yet been done for something like mail (to the best of my knowledge).
Thoughts moving forward
Single mailboxes do not make strong conceptual sense for the process of organizing what is basically memory. Tagging approaches combined with machine learning and temporal decay are going to be more well suited. Where items fit many different topics and the importance of those topics is a constantly decaying function.
As far as recording email behavior attributes, things that would seem extremely beneficial, are the amount of time you spend reading a message to either delete, or classify it, obviously normalized by the length of the message. That data is not currently available and would need to be made so through a specific interface.
Additionally, I believe in analyzing some of these results that there should be detectable latent variables in email structure, that are the social importance of the sender. Simple recording of the number of message to an individual that are reply vs forward vs receipt vs sent to.
Part 2
Part 2 is to be completed over IAP, will consist of:
- Finish Actor Critic RL implementation and test for comparison.
- Design better UI for accessing and manipulating, a significant part of this problem is not related to machine learning at all, but is in fact a UI issue.
- Test the social graph theory, where flow (messages) into an out of a user node is used to approximate relative social importance to the individual.
- Test the theory of collaborative filtering of mailing-lists as being beneficial.
Software
Software used was the libsvm client, python modules, numpy, scipy, bayesian libraries, django, libgmail, procimap, and several ruby gems, which were extended and modified. All source code can be downloaded for examination.
Related Projects
Mail Classifier (Thunderbird Plugin)Popfile (Spam Filter)
Gurgitate-mail (User rules)
Proc-mail (User rules)
SpamBayes (Spam Filter)
Resources
Sahami et al. A Bayesian approach to filtering junk e-mail. AAAI-98 Workshop on Learning for Text Categorization (1998)Tailby et al. Email classification for automated service handling. Proceedings of the 2006 ACM symposium on Applied computing (2006)
Picard and Minka Interactive Learning Using a "society of Models". (1996)
Klimt et al. The Enron Corpus: A New Dataset for Email Classification Research. LECTURE NOTES IN COMPUTER SCIENCE (2004)
Kiritchenko et al. Email classification with co-training. Proceedings of the 2001 conference of the Centre for … (2001)
Rohall et al. ReMail: a reinvented email prototype. Conference on Human Factors in Computing Systems (2004)
Kannan et al. On clusterings: Good, bad and spectral. Journal of the ACM (JACM) (2004)
Viégas et al. Visualizing email content: portraying relationships from conversational histories. Proceedings of the SIGCHI conference on Human factors in … (2006)
Byron et al. Stacked Graphs–Geometry & Aesthetics. Visualization and Computer Graphics (2008)
This data brought to you by Doug Fritz, hope you enjoyed it. Still working on this so if you have feedback or suggestions, please email me at doug <at> media.