Modeling Head Nods for Recognition
Pattern Rec 2010
Jin Joo Lee
When we interact with a person, we have a whole spectrum of communication. Spoken words are the most obvious forms of communication, but nonverbal cues like facial expressions and head gestures also convey important information.
In particular, head nodding is a cue that can show understanding, approval, and agreement [1].
For my project, I will try to detect head nods through two different pattern recognition algorithms.
This website will explore using HMMs (Hidden Markov Model) and HCRFs (Hidden Conditional Random Fields) to model a conversational head nod.
Introduction
Our colleagues at Northeastern University perform many studies looking at nonverbal cues in a social interaction. They have participants come in and talk to each other for about 5 minutes. A list of generic conversation topics were given such as “How do you like Boston” and “What do you do for fun.”
These interactions were video recorded, and each interaction was coded for the follow cues:
Smiling Lean Nod Looking away Shake Laughing
Hand touch Hair touch Body touch Eye contact
For my project, I only looked at the nodding data because there were many instances in which it occurred, making training easier. For future work, I would like to gather more video data in order to investigate the other nonverbal cues.
An important thing to note is the context of the nodding data. In prior work like [1] and [2], the nodding data was collected by evoking the participants to nod through a series of questions. The nod data used for this project is extracted from real, naturally occurring conversational nods. Unfortunately, these nods are sometimes more subtle and harder to detect, which presents an unique problem to the nodding recognition.



Camera A
Camera B
Camera C
All the videos from the study mentioned previously were processed by the Google Face Tracker [4] to extract the 22 face points seen in Figure 1 plus the following features:
Face Yaw Angle Face Roll Angle Face Pitch Angle
Face size Face Center X Face Center Y
There were 41 dyads in total which meant 82 different participant videos, which were all processed using the google face tracker.
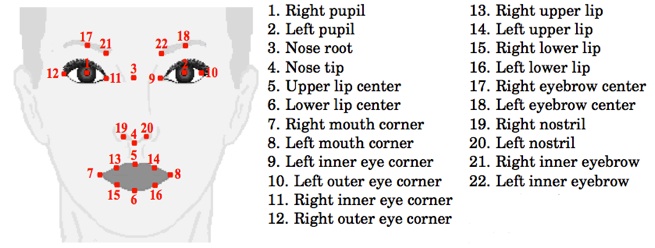
Figure 1. Points tracked using Google Face Tracker (figure from [3])


Study Data


Face Tracking Data

